Understanding Retrieval-Augmented Generation (RAG)
Introduction
Retrieval-Augmented Generation (RAG) represents a paradigm shift in artificial intelligence, fundamentally changing how we approach knowledge-intensive tasks. This revolutionary technique combines the generative capabilities of large language models (LLMs) with the precision of information retrieval systems, creating AI systems that can access, understand, and synthesize information from vast knowledge bases in real-time.
Unlike traditional language models that rely solely on their training data, RAG systems can dynamically retrieve relevant information from external sources, ensuring responses are not only fluent but also factually accurate and up-to-date. This makes RAG particularly valuable for applications requiring current information, domain-specific knowledge, or access to private datasets.
The Evolution of Language Models
The journey to RAG began with the limitations of traditional language models. Early models like GPT-1 and BERT, while impressive, were constrained by their training data cutoff dates and inability to access external information. As these models grew larger and more sophisticated, they demonstrated remarkable capabilities in text generation and understanding, but they remained fundamentally static systems.
The breakthrough came with the realization that combining the generative power of LLMs with dynamic information retrieval could create more capable and reliable AI systems. This led to the development of RAG, which represents a hybrid approach that leverages the best of both worlds: the linguistic understanding of LLMs and the factual accuracy of information retrieval systems.
Why Do We Need RAG?
Large Language Models, despite their impressive capabilities, face several critical limitations that RAG addresses:
- Stale Knowledge: Once trained, LLMs cannot access new information unless retrained, which is extremely costly and time-consuming. This creates a knowledge cutoff problem where models become outdated quickly.
- Hallucination: LLMs sometimes generate plausible-sounding but factually incorrect information, especially when asked about topics outside their training data.
- Domain Adaptation: Adapting LLMs to specific domains or private datasets requires extensive fine-tuning, which is resource-intensive and may not always be feasible.
- Limited Context Window: Even the largest models have context limitations, making it difficult to incorporate extensive external knowledge.
- Lack of Source Attribution: Traditional LLMs cannot provide sources for their information, making it difficult to verify claims. RAG addresses these issues by allowing models to retrieve relevant documents from external sources in real-time, grounding their responses in factual, up-to-date information while providing source attribution.
How Does RAG Work?
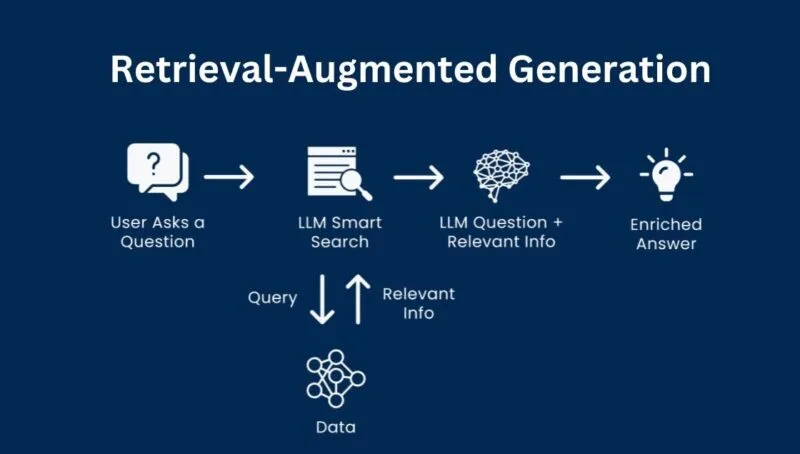
RAG operates through a sophisticated two-stage process that combines retrieval and generation:
- Retrieval Phase: When a user submits a query, the system first converts the query into a vector representation using an embedding model. This vector is then used to search a pre-indexed knowledge base for the most relevant documents or passages. The retrieval can use various methods:
- Dense vector search using embeddings
- Sparse keyword-based search (like BM25)
- Hybrid approaches combining both methods
- Semantic search using transformer-based models
- Generation Phase: The retrieved documents, along with the original query, are fed into a language model as context. The model then generates a response that synthesizes information from both the query and the retrieved content. This process ensures that the generated answer is both fluent and grounded in real data. The key innovation is that this process happens in real-time, allowing the system to access the most current information available in the knowledge base.
RAG Architecture Deep Dive
A comprehensive RAG system consists of several interconnected components, each playing a crucial role in the overall functionality:
- Document Processor: Converts raw documents into a searchable format, handling various file types (PDF, Word, HTML, etc.) and extracting text content.
- Embedding Model: Converts text into dense vector representations that capture semantic meaning. Popular choices include OpenAI's text-embedding-ada-002, Sentence-BERT, or custom fine-tuned models.
- Vector Database: Stores and indexes the document embeddings for efficient similarity search. Popular options include Pinecone, Weaviate, Chroma, or Elasticsearch.
- Retriever: The core component that finds relevant documents using various search strategies. Can be dense retrieval, sparse retrieval, or hybrid approaches.
- Generator: A language model (GPT, Claude, or open-source alternatives) that synthesizes the final answer using retrieved context.
- Knowledge Base: The external source of truth, which can be a collection of documents, databases, APIs, or even live web content.
- Reranker (Optional): A component that re-ranks retrieved documents to improve relevance before generation. The architecture can be further enhanced with components like query expansion, result filtering, and response validation.
Types of RAG Systems
RAG systems can be categorized based on their architecture and approach:
- Naive RAG: The simplest form where documents are retrieved and passed directly to the generator without additional processing.
- Advanced RAG: Incorporates techniques like query expansion, document reranking, and better context management.
- Modular RAG: Uses separate, specialized models for different tasks (retrieval, reranking, generation) that can be optimized independently.
- End-to-End RAG: Jointly trains the retriever and generator, allowing them to learn optimal representations together.
- Self-RAG: Introduces self-reflection mechanisms where the model can decide when to retrieve additional information or when to generate responses based on its current knowledge.
Benefits of RAG
RAG offers numerous advantages that make it particularly valuable for real-world applications:
- Up-to-date Information: RAG can provide information beyond the model's training data, making it ideal for rapidly changing fields like technology, finance, or current events.
- Domain Adaptation: Easily plug in custom or private data sources to tailor the system to specific industries, organizations, or use cases.
- Reduced Hallucination: By grounding answers in real documents, RAG significantly reduces the risk of generating incorrect or misleading information.
- Source Attribution: Users can verify information by checking the original sources, increasing trust and transparency.
- Scalability: The knowledge base can be expanded or updated without retraining the entire model, making it cost-effective and flexible.
- Privacy and Security: Sensitive information can be kept in private knowledge bases while still leveraging the power of large language models.
- Cost Efficiency: Reduces the need for frequent model retraining by updating only the knowledge base.
Challenges and Limitations
Despite its advantages, RAG systems face several significant challenges:
- Retrieval Quality: The effectiveness of RAG depends heavily on the quality of the retriever. Poor retrieval can lead to irrelevant or incomplete answers, even with a perfect generator.
- Latency Issues: Retrieving and processing external documents introduces latency, especially with large knowledge bases or complex retrieval strategies.
- Context Window Limitations: Even with retrieval, there are limits to how much context can be effectively used by the generator.
- Context Integration: Combining information from multiple retrieved documents in a coherent and logical way remains a challenging problem.
- Evaluation Complexity: Measuring the factual accuracy, relevance, and quality of generated answers is difficult and often requires human evaluation.
- Knowledge Base Maintenance: Keeping the knowledge base up-to-date and ensuring data quality requires ongoing effort and resources.
- Retrieval-Generation Mismatch: The retrieved documents might not always align perfectly with what the generator needs to produce high-quality responses.
Real-World Use Cases
RAG has found applications across numerous industries and domains:
- Enterprise Knowledge Management: Internal tools that help employees find information from company documentation, policies, and procedures.
- Customer Support: AI-powered chatbots that provide accurate, up-to-date responses by retrieving from FAQs, manuals, and support articles.
- Legal and Medical Q&A: Systems that help professionals find precise answers in large, domain-specific document collections.
- Research and Development: Tools that help researchers synthesize information from scientific literature and technical documents.
- Financial Services: Systems that provide up-to-date market information and regulatory guidance.
- Education: Intelligent tutoring systems that can answer questions based on course materials and textbooks.
- Content Creation: Tools that help writers and content creators research and fact-check information.
- E-commerce: Product recommendation systems that can answer detailed questions about products and services.
Popular RAG Frameworks and Tools
The RAG ecosystem has grown rapidly, with numerous frameworks and tools available:
- Haystack (Python): A comprehensive open-source framework for building search systems and RAG pipelines with support for various retrievers and generators.
- LlamaIndex: A data framework specifically designed for connecting LLMs with external data sources, offering both simple and advanced RAG capabilities.
- LangChain: A popular library for chaining together LLMs and retrieval components, with extensive support for various data sources and models.
- OpenAI API with Retrieval: Allows developers to augment GPT models with custom retrieval capabilities using OpenAI's infrastructure.
- Pinecone: A managed vector database service that makes it easy to implement semantic search for RAG applications.
- Weaviate: An open-source vector database with built-in support for various ML models and RAG workflows.
- Chroma: A lightweight vector database designed specifically for AI applications and RAG systems.
- Elasticsearch with ML: Uses Elasticsearch's machine learning capabilities for semantic search in RAG applications.
Implementation Best Practices
Successfully implementing RAG requires careful attention to several key areas:
- Knowledge Base Curation: Ensure your documents are high-quality, well-organized, and regularly updated. Poor quality input leads to poor quality output.
- Retrieval Optimization: Use appropriate embedding models and fine-tune retrievers for your specific domain. Consider hybrid approaches that combine dense and sparse retrieval.
- Context Management: Implement strategies to handle context window limitations, such as document summarization or hierarchical retrieval.
- Performance Monitoring: Continuously evaluate the accuracy, relevance, and quality of generated answers using both automated metrics and human evaluation.
- Security and Privacy: When using private or proprietary data, ensure compliance with privacy regulations and implement appropriate security measures.
- Scalability Planning: Design your system to handle growing knowledge bases and increasing query volumes.
- User Experience: Consider how users interact with your RAG system and provide clear feedback about sources and confidence levels.
Advanced RAG Techniques
As RAG systems mature, several advanced techniques have emerged to improve their performance:
- Query Expansion: Automatically expand user queries with related terms to improve retrieval recall.
- Document Reranking: Use specialized models to rerank retrieved documents based on relevance to the specific query.
- Multi-hop Reasoning: Enable the system to perform multiple retrieval steps to answer complex questions that require information from multiple sources.
- Retrieval-Augmented Fine-tuning: Fine-tune the generator on retrieved documents to improve its ability to use external information.
- Adaptive Retrieval: Dynamically adjust retrieval strategies based on query complexity or user feedback.
- Knowledge Graph Integration: Combine RAG with knowledge graphs to enable more structured reasoning and fact verification.
- Multi-modal RAG: Extend RAG to handle not just text but also images, audio, and other media types.
Evaluation and Metrics
Evaluating RAG systems requires considering multiple dimensions of performance:
- Retrieval Metrics: Precision, recall, and F1 score for document retrieval, often measured using human-annotated relevance judgments.
- Generation Quality: Fluency, coherence, and factual accuracy of generated responses, typically evaluated using automated metrics like BLEU, ROUGE, or BERTScore.
- End-to-End Performance: Overall system performance measured through task-specific metrics or human evaluation.
- Latency and Throughput: System performance metrics including response time and queries per second.
- User Satisfaction: User feedback and engagement metrics to measure real-world effectiveness.
- Factual Accuracy: Verification of claims against ground truth or authoritative sources.
- Source Attribution Quality: Accuracy of source citations and relevance of retrieved documents.
Future Directions and Research
RAG is an active area of research with several promising directions:
- Improved Retrieval: Development of more sophisticated retrieval methods that can better understand query intent and document relevance.
- Better Integration: Research into how to more effectively combine retrieved information with generated text.
- Real-time Knowledge: Systems that can access and incorporate live, streaming data sources.
- Multi-modal Capabilities: Extending RAG to handle diverse data types including images, audio, and video.
- Reasoning and Planning: Advanced RAG systems that can perform complex reasoning and multi-step problem solving.
- Personalization: RAG systems that can adapt to individual users' preferences and knowledge needs.
- Efficiency Improvements: Techniques to reduce latency and computational requirements while maintaining quality.
- Evaluation Methods: Better automated evaluation methods that can assess RAG system quality without human intervention.
Getting Started with RAG
If you're interested in implementing RAG, here's a practical roadmap:
- Start Simple: Begin with a basic RAG implementation using existing frameworks like LangChain or Haystack.
- Choose Your Data: Identify and prepare your knowledge base, ensuring data quality and proper formatting.
- Select Models: Choose appropriate embedding models and language models based on your requirements and budget.
- Implement Retrieval: Set up vector storage and retrieval mechanisms using tools like Pinecone or Chroma.
- Build the Pipeline: Connect retrieval and generation components to create your RAG system.
- Evaluate and Iterate: Test your system thoroughly and continuously improve based on performance metrics.
- Scale and Optimize: As your system grows, implement advanced techniques and optimizations. Remember that RAG is not a one-size-fits-all solution, and the best approach depends on your specific use case, data, and requirements.
Conclusion
Retrieval-Augmented Generation represents a fundamental shift in how we approach AI systems that need to work with knowledge. By combining the generative power of large language models with the precision of information retrieval, RAG enables the creation of AI systems that are not only fluent and intelligent but also accurate, up-to-date, and trustworthy.
As the field continues to evolve, RAG will play an increasingly important role in building the next generation of AI applications. Whether you're building enterprise knowledge systems, customer support tools, or research assistants, understanding and implementing RAG can significantly enhance the capabilities and reliability of your AI solutions.
The key to success with RAG lies in understanding its strengths and limitations, choosing the right tools and techniques for your specific use case, and continuously iterating and improving based on real-world performance. With the right approach, RAG can transform how your organization leverages AI to work with knowledge and information.